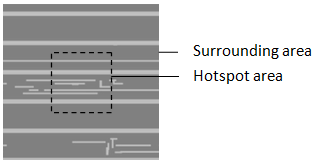
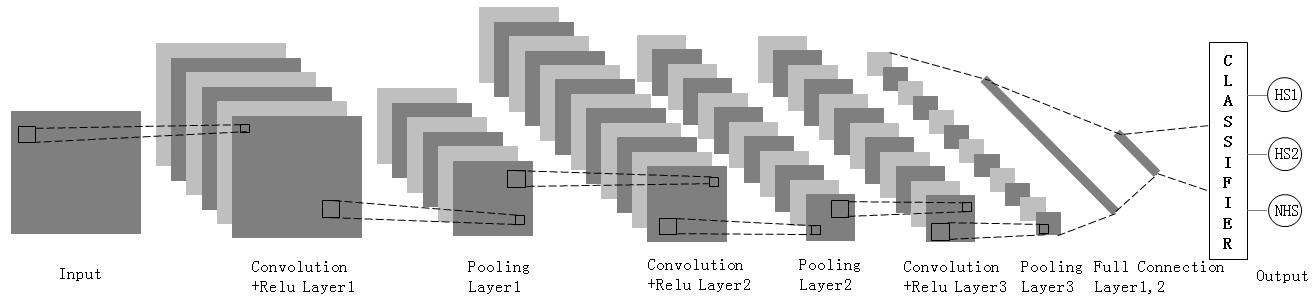
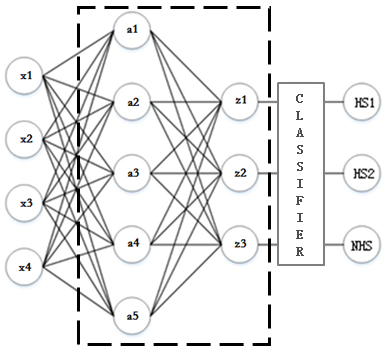
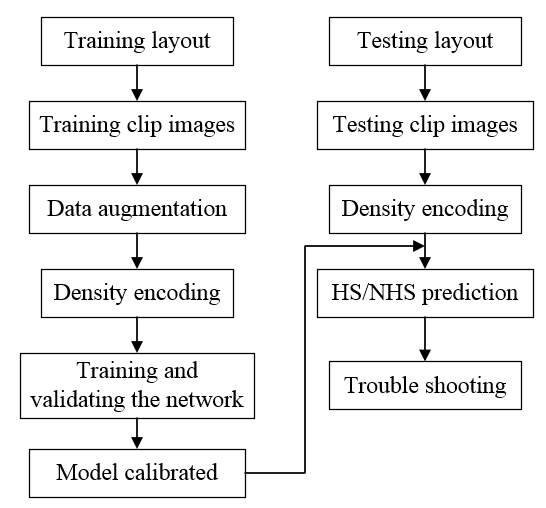
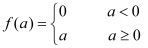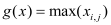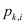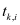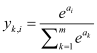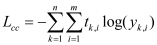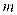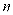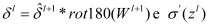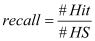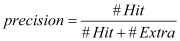This paper uses the data sets of ICCAD to train and verify the designed network. The details are as Table 1.
Table 1.
ICCAD data sets. | Dataset | Train | Test | Process |
| #HS | #NHS | #HS | #NHS |
| ICCAD-1 | 99 | 340 | 226 | 319 | 32nm |
| ICCAD-2 | 174 | 5285 | 499 | 4146 | 28nm |
| ICCAD-3 | 909 | 4643 | 1847 | 3541 | 28nm |
| ICCAD-4 | 95 | 4452 | 192 | 3386 | 28nm |
| ICCAD-5 | 26 | 2716 | 42 | 2111 | 28nm |
All training sets are divided into 3:2 for training and cross validation. The effects of different batch sizes, learning rate, loss function and optimization methods are analyzed and compared. The differences of every result are explained. After four experiments, the precision and recall of the best model are tested on testing set.
Experiment 1 analyzed the effect of training batch [16] on the model. Keep the learning rate, loss function and optimization method unchanged. Training results of ICCAD-1 data set are as Figure 5. Increasing batch size within a certain range can improve memory utilization and reduce the number of iterations every epoch. Usually, the greater the batch size, the more accurate the gradient descent direction is, and the smaller the training vibration. But too large batch size has the problems of memory overflow, slow convergence and local optimum. Therefore, we need to consider the size of batch size based on factors such as time, memory space and accuracy. For ICCAD-1 data set, batch size 20 is reasonable to have a high validation accuracy and appropriate computing time.
Figure 5.
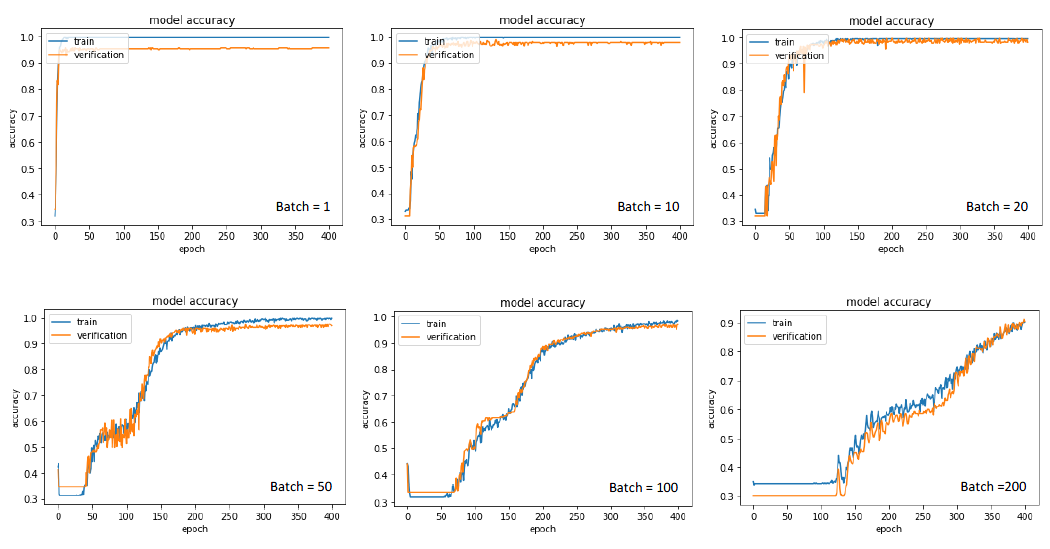
Effects of the batch size on model accuracy. Experiment 2 analyzed the effects of Mini-batch Gradient Descent (MGD) learning rate (LR) [17] on the model. Keep the batch size, loss function, and optimization method unchanged, and adjust the learning rate. Experimental results are as Figure 6. It is proved that too large learning rate leads to an over update which makes the model difficult to converge. In addition, because the activation function is ReLU, too large learning rate will make many nodes turn to 0 after iterations of activation functions and the gradient will stop to decline. In this experiment, when the learning rate is under 0.01, the model can converge and the accuracy is acceptable. And the smaller learning rate needs more iterations to achieve convergence. Training time also increases correspondingly. It is remarkable that too small learning rate is not only time consuming but also could cause local optimum. Therefore, the choice of learning rate should be considered taking the accuracy, training time, and optimization methods into account.
Figure 6.
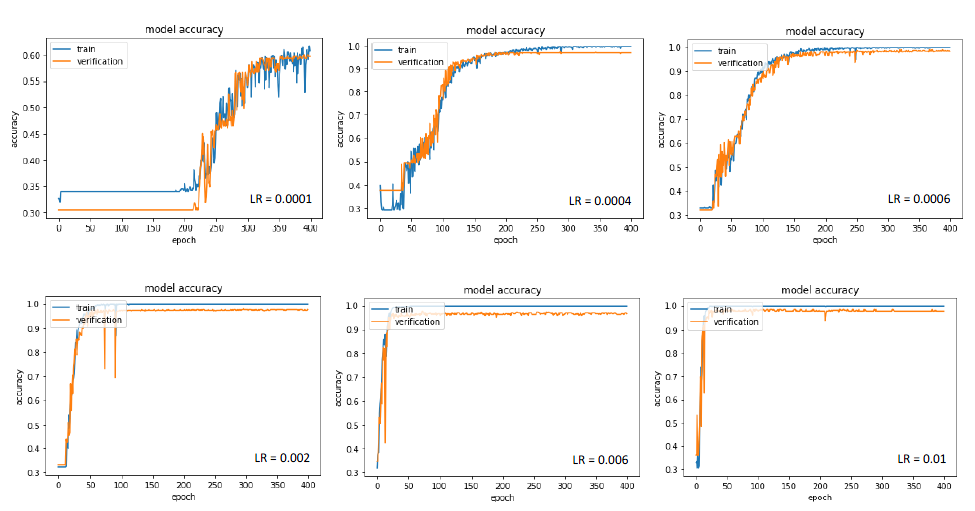
Effects of learning rate on model accuracy. Experiment 3 analyzed the effects of loss function [18] on the model. Keep the batch size, learning rate, and optimization method unchanged, and adjust the loss function. Training results of data set ICCAD-1 are as Figure 7. Squared_hinge is a classification method based on the maximum boundary. It maximizes the minimum distance between the classification surface and the feature vector to optimize the model. It focuses on the features near the classification surface. Categorical_crossentropy is a classifier based on probability distribution, which reduces the probability of misclassification by cross entropy function and pays attention to all features. We can see that the two loss functions both converge well, and the Squared_hinge’s convergence speed is slower, which is related to the features of the training set. Considering the explanatory property and robustness of the classification model, the Categorical_crossentropy is chosen as the loss function in this paper.
Figure 7.
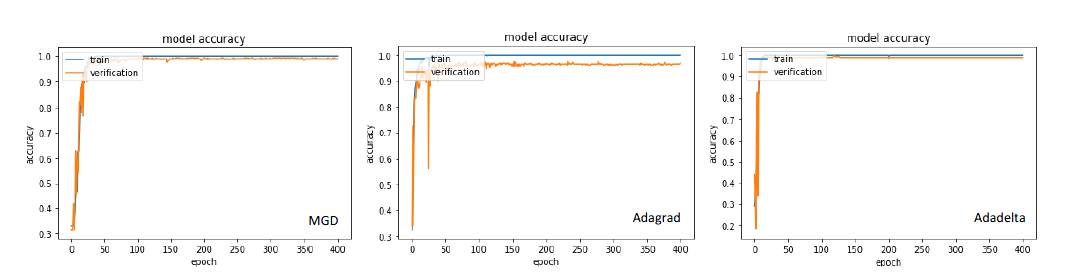
Effects of the loss function on model accuracy. Experiment 4 analyzed the effects of optimization methods [19] on training results. Keep the batch size, initial learning rate, and loss function unchanged, and adjust the optimization method. The experimental results are as Figure 8. MGD is the most common optimization method which calculates the gradient of mini-batch every iteration and then updates the parameters with the same learning rate. The choice of learning rate will directly affect the performance of optimization. Adagrad imposes a constraint on the learning rate. It increases the learning rate of more sparse parameters and decreases the learning rate of parameters which upgrades faster in the past. However, Adagrad has a problem of early stop when training a deep network because of its monotonic adjusting strategy. While Adagrad accumulates all the squares of the gradient before calculating the corresponding learning rate, Adadelta adapts learning rates based on a moving window of gradient updates. It is shown that the adaptive learning methods converge more quickly which doesn’t need a careful design of the initial learning rate. Adadelta is chosen as the final optimization method for its learning speed and robustness. It is worth mentioning that MGD is still widely used nowadays for its final tune ability and flexibility for researching.
Figure 8.
Effects of the optimization method on model accuracy.